왜 모니터링을 해야할까?
어떤 기능이든 배포가 끝이 아니다. 유저들이 우리가 의도한대로 쓰는지, QA에 찾지 못한 오류는 없었는지, 기존 기능이랑 융합은 어떤지 등 유기적으로 잘 돌아가는지 오랜기간 확인해봐야한다.
개인적으로 생각하는 제일 중요한것중에 하나는 일단 편해야한다는 것이다. 심미적으로 이쁜것도 좋긴 하지만 일단 편해야한다. 유저가 불편함을 느끼는 이유는 다양한 원인이 있을 수 있다.
어떤 제품을 몇년간 개발하고 유지보수 하다보면 다양한 불편함 CS를 볼 수 있다.
- 느리다
- 액션을 했는데 예측한 대로 동작하지 않는다
- 보이는게 거슬리다
- 오류가 난다 등
만약 모니터링에 대한 준비가 안되어있는 상태에서 이런 CS가 인입되면 담당하는 개발자는 벙찌게 된다. 지금 가지고 있는 경험과 지식으로 최대한 상상해서 답변을 주게 된다. 근데 그러다보면 내가 상상하고 있는게 유저의 환경이랑 맞는지 확인질문도 해봐야하고, 직접 재현도 해봐야하고 시간이 오래 걸린다 -> 내 자신이 불편해진다.
CS인입 뿐만 아니라 내가 만드는 제품의 성능을 개선하고 싶을 때 모니터링 도구가 없다면 어떤것부터 어떻게 해야할 지 감을 잡기가 어렵다.
모니터링 도구를 잘 써야하는 이유를 한 줄로 요약하면 메타인지를 잘하기 위함이다. 제품의 어디가 어떻게 돌아가고 있는지 인지하고 있으면 오류대응을 하거나 개선을 하고 싶을 때 뭘 해야하는지 쉬워진다.
Datadog RUM에서 어떤걸 봐야할까?
평소에 궁금증 있는 것부터 1개씩 확인해 보는게 좋다.
성능 지표
Performance Monitoring 페이지
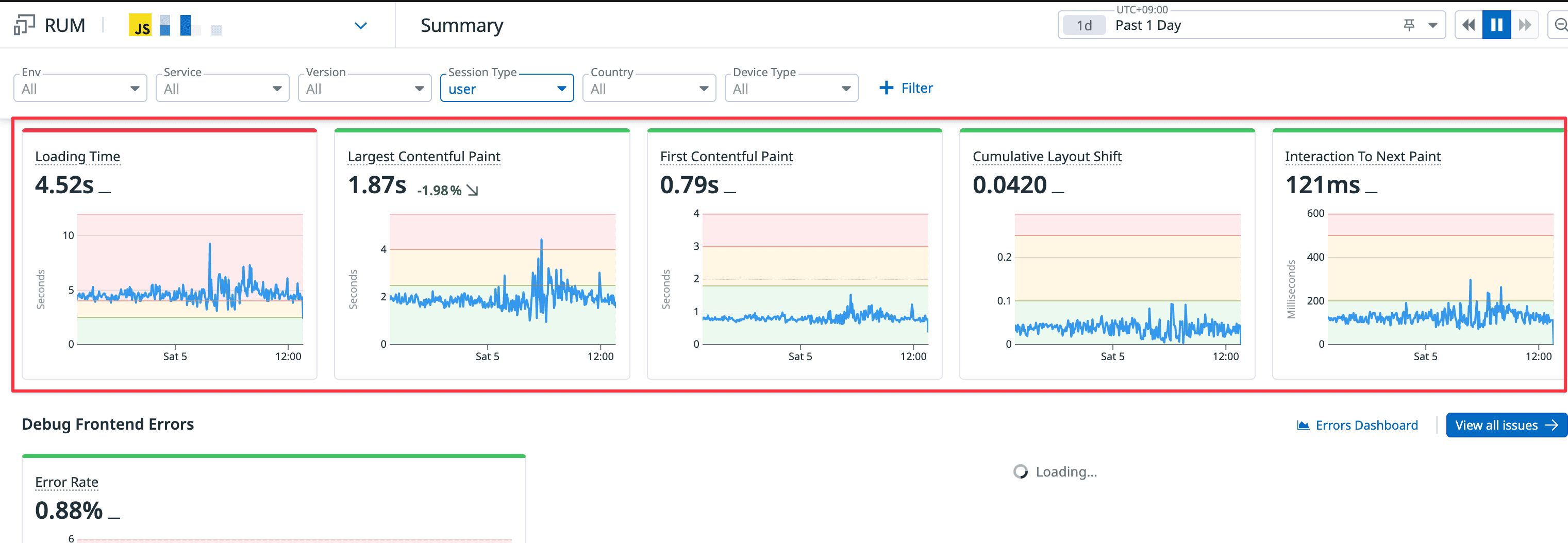
RUM을 사용하기만해도 Application Id 단위로 전체 사이트의 Web Vital을 보여준다.
- 필터를 사용해 특정 페이지, 특정 디바이스, 특정 환경 아주 다양하게 필터를 할 수 있다.
- 우측 상단의 기간을 설정해서 과거에 비해 어떻게 변화했는지 확인할 수 있다.
- 시간에 따른 각 지표를 확인할 수 있다.
- 당연하게도 유저가 많은 시간대에 느려지는걸 확인할 수 있다.
- 그럼 어떤 API가 과부하에 취약한지 알 수 있게되고, 어떤것부터 속도를 개선해야하는지 우선순위를 정할 수 있게 된다.
- 아래 이미지 처럼 각 path별 성능을 보여주는 영역도 있다.

느린 이미지, 리소스 찾기
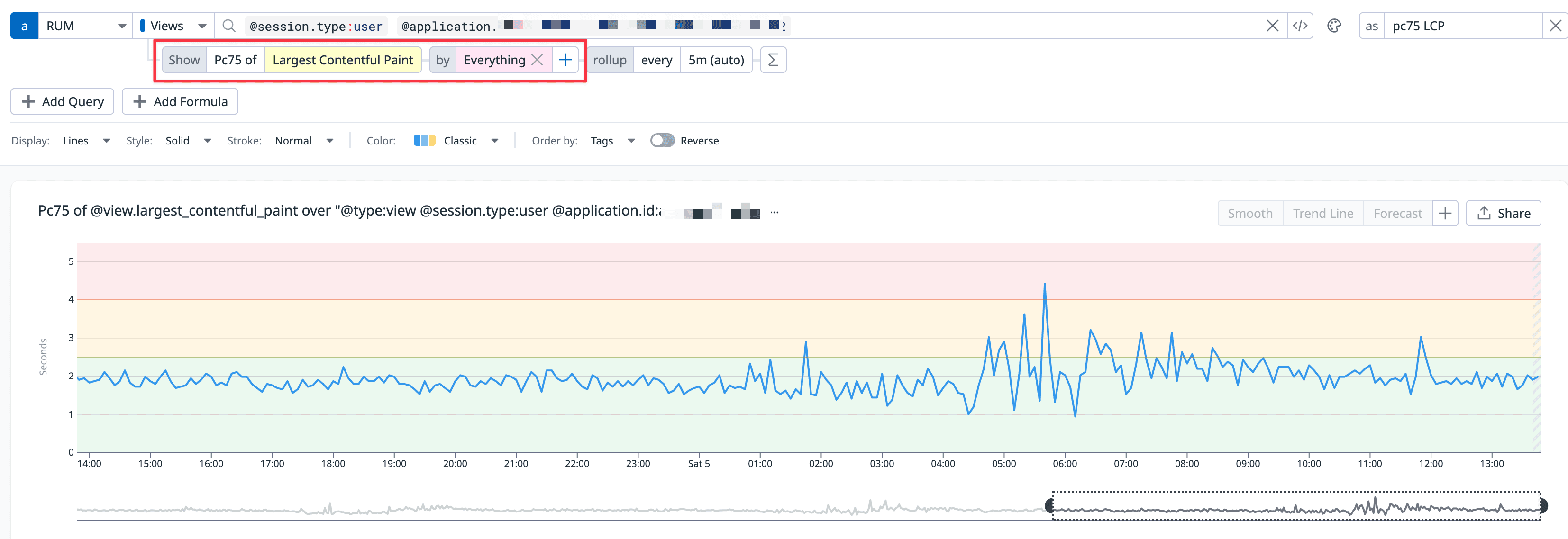 위에서 Web vitals을 보여줄 때 사용된 데이터독 쿼리를 차용해 본인이 원하는 필터를 만들수도 있다. (Performance Monitoring 페이지에서 기본으로 보여주는 섹션도 데이터독 쿼리를 기본으로 세팅해서 보여주는 것이다.)
위에서 Web vitals을 보여줄 때 사용된 데이터독 쿼리를 차용해 본인이 원하는 필터를 만들수도 있다. (Performance Monitoring 페이지에서 기본으로 보여주는 섹션도 데이터독 쿼리를 기본으로 세팅해서 보여주는 것이다.)
만약 사용자가 생성하는 컨텐츠 기반 서비스를 하는 회사라면 컨텐츠가 빨리 로드되는게 중요할 것이다. datadog RUM 옵션에서 trackResources 옵션을 true로 설정했다면 PerformanceResourceTiming API기반으로 각 요청의 속도를 측정해서 자동으로 기록해준다.
이를 @resource 관련 메트릭으로 쿼리를 사용해 조회할 수 있다. 다양한 정보를 저장하지만 주로 사용하는 건 @resource.duration (리소스를 로드하는 데 걸린 전체 시간), @resource.size (리소스 사이즈)이다.
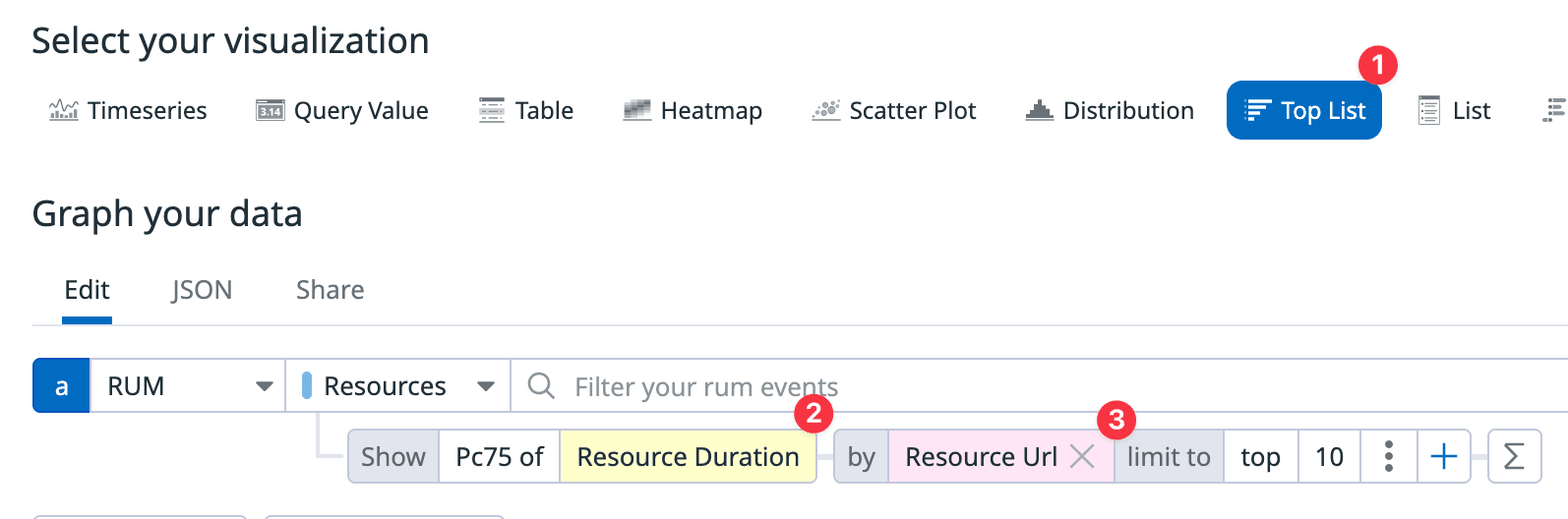
- 시각화 종류를
Top List로 설정한다. - 보여지는 메트릭을 리소스 로드 시간으로 설정한다.
- 분류기준을 리소스 URL로 설정하고 내림차순으로 정렬한다.
이제 어떤 요청이 우리 사이트에서 제일 느린지 알 수 있다. 이 필터를 설정하고 나니 예상치 못한 리소스가 제일 느린 요청이여서 놀랐다. 아무래도 유저가 생성하는 컨텐츠가 있다보니 복붙해 오는 경우가 잦은데, 이 때문에 외부 CDN이 있었고 이 요청이 제일 느린편에 속했다. (그래서 이 외부 CDN 리소스들을 어떻게 하면 좋을지 논의했었는데 당장 급한 사안이 아니기도하고 일부여서 일단 스킵하기로 결정했었다)
이런식으로 모니터링을 하다보면 제품에 대해 내가 뭘 모르고 있었는지 메타인지를 계속 하게 된다.
에러
운영 배포된 것들은 항상 버그때문에 오류가 발생하기 마련이다. 완벽하가 예방하는 것보다 문제가 발생했을 때 빠르게 대응하는게 더 쉽다고 생각한다. 다음은 에러를 빠르게 대응하기 위해 했던 과정들이다.
- 일단 에러를 최대한 기록할 수 있는 만큼 기록한다.
- 한 번에 에러에 대한 대응법들을 착착착 만들면 좋겠지만 현실적으로 불가능하다.
- Monitors 기능을 사용해 특정 시간(5분)안에 임계치 이상 에러가 발생하면 알람을 받도록 설정한다. (예를 들면 슬랙)
- 에러 알람이 슬랙으로 올 때마다 확인한다.
- 이 때 Session Replay 옵션을 활성화해 유저가 어떤 행동을 했는지 기록하도록 설정했다면 어떤 에러가 왜 발생했는지, 실제로 유저 경험에 불편함을 끼쳤는지 확인하기 편하다.
- 하지만 비용이 비싸다. 무료로 대체할 수 있는 제품으로썬 마이크로 소프트의 Clarity가 있다.
- 일정 기간동안 에러와 CS인입을 확인하다보면 패턴이 보인다. 그 패턴을 기반으로 에러 알람을 고도화한다.
- 에러 유형 별로 에러를 구별하기 쉽게 만들자.
- 에러의 특성에 따라 카디널리티 높은 데이터를 에러와 함께 남기자
- 예를 들어 shaka-player를 사용중이라면 영상 재생에러 코드와 재생환경을 에러객체에 같이 남기면 원인 파악할 때 도움이 된다.
- Monitors에 에러 특성별로 설정을 따로 해서 각각 알람이 오도록하자. 알람이 트리거되는 임계치도 다르게 맞춰주자
- 알람이 너무 많이 울리면 개발자의 민감도가 떨어진다.
- 불필요한 알람은 beforeSend 옵션을 써서 데이터독에 보내지 않도록 하자
서비스 분석
Product Analytics페이지
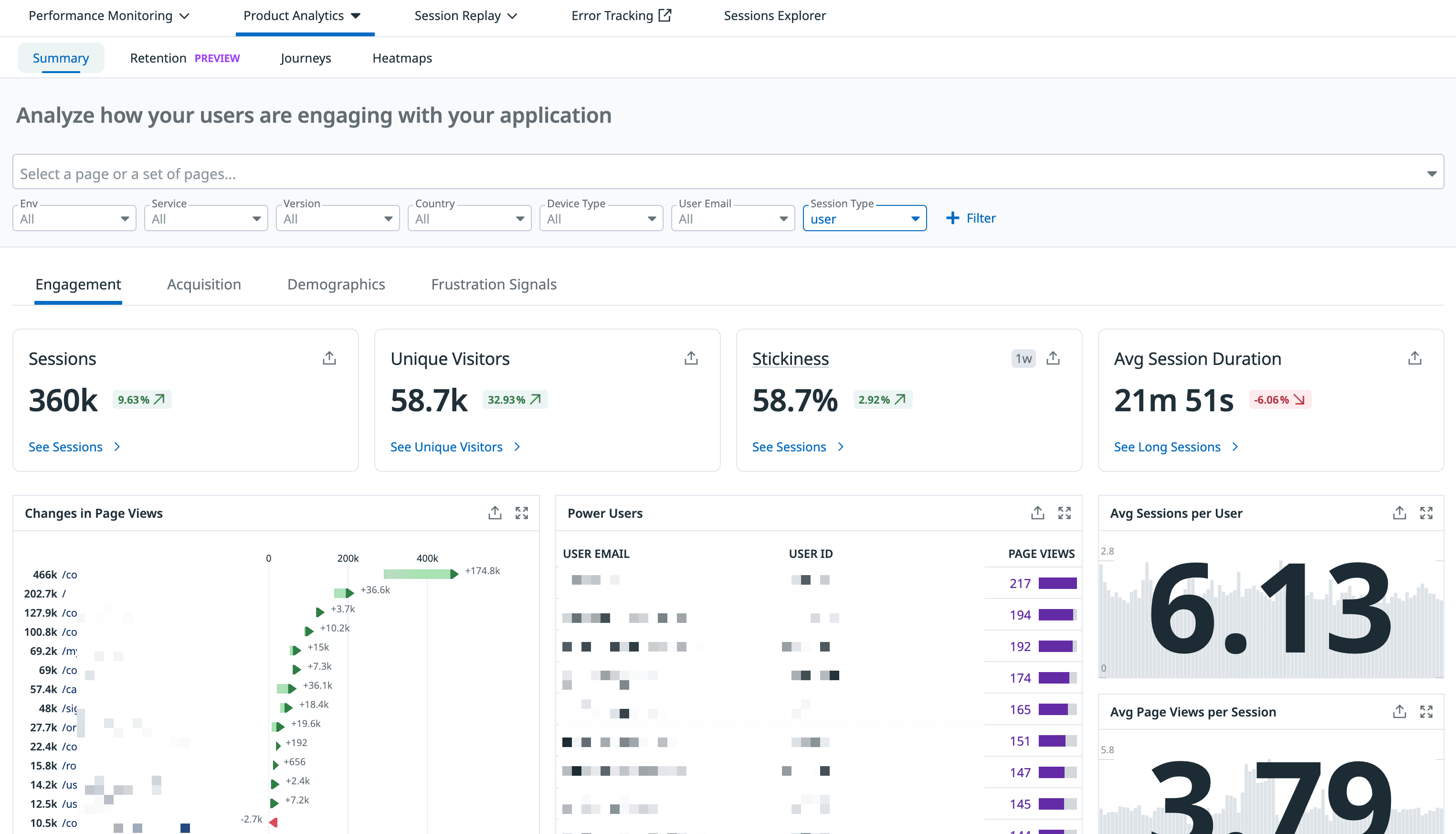
우리가 의도한 대로 유저가 사용을 하는지, 어느 페이지가 인기가 좋은지, 어느 버튼이 가장 많이 눌리는지 등을 한 번에 볼 수 있다. 이 정보 또한 필터를 사용해 다양한 조건으로 살펴볼 수 있다.
이 기능을 활용해 학습하는 페이지에 유저가 머문 시간의 평균을 확인해 본 적이 있었다. 신기하게도 OS, 브라우저가 달라도 평균적으로 시간이 50분에 수렴했다. 학교에서 1교시를 50분에 근접하게 설정했던게 괜히 그런게 아니구나 싶었다.
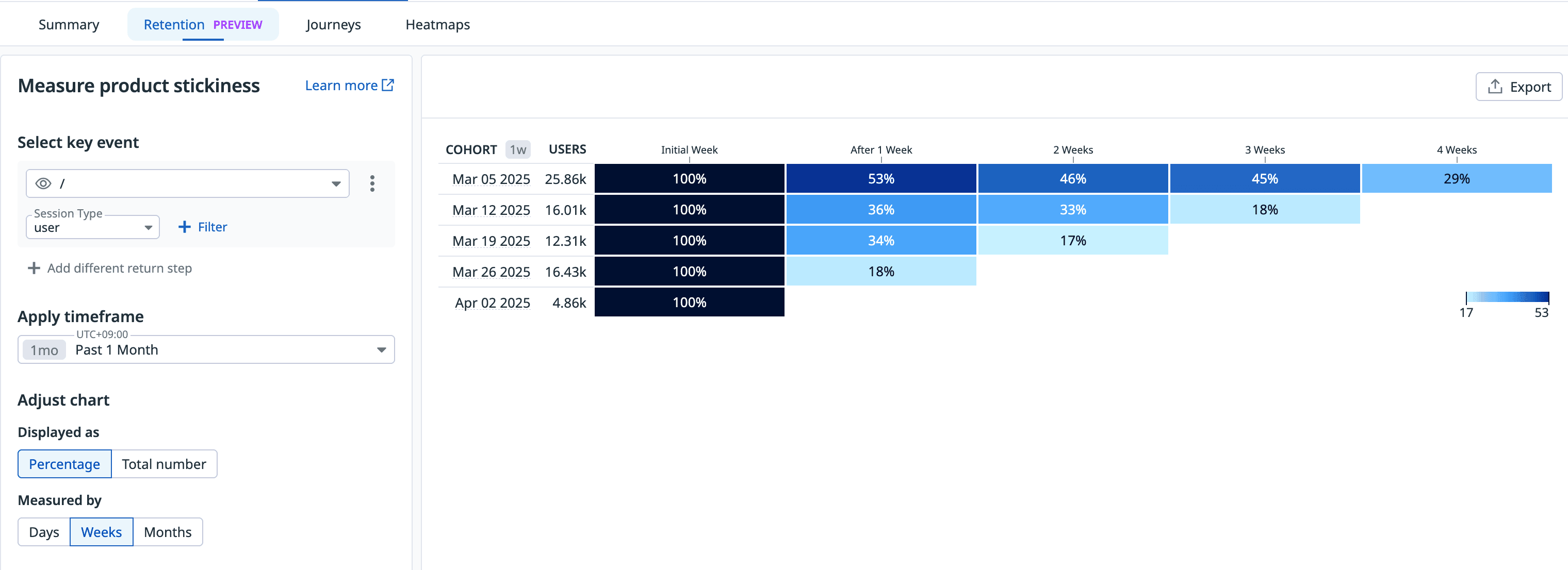
리텐션 페이지에선 특정 Path별로 유저의 리텐션을 볼 수 있다. 특정 기간별로 설정이 가능하다.
이외에도 유저의 이동이 어디서 어디로 흐르는지 볼 수 있는 Funnel 특정 페이지에서 어느 곳을 자주 클릭하는지 볼 수 있는 Heatmap 등을 제공한다.